[A more technical post follows]
My most recent paper, out on the arXiv today, is very exciting to me because it seems to be a genuinely new way of computing some important quantities and it is devilishly simple. So simple that I worried for months that it is all super-obvious to everyone. But another voice within me said to myself: Well if it is so obvious, why has nobody published it? Another (paranoid) voice within said: Maybe someone has published this method, and I just can’t find it in the literature…
Well, I decided that the best way to find out for sure is to put it on the arXiv and within a short time someone will email to say that I missed their important work. So, while I wait for that email (as I start writing it’s only been 30 minutes since it has been “out there”, so there’s time), let me say a few things about why I like the many results in the paper.
I was already pleased enough with the core part of the paper that I was going to write a swift four-pager about it back in February. The core point being that I figured out how to build on work I’d done in a paper back in 2024 (expanded on with followup work I did with Wasif Ahmed and Krishan Saraswat, a student and postoc). Back in 2024, I found (here) a really nice way (almost miraculous in how it worked) of writing all the corrections to the spectral density of a class of models in terms of one function  and its derivatives. It was obtainable from one simple ordinary differential equation (ODE) called the Gel’fand-Dikii equation, which takes in the function
and its derivatives. It was obtainable from one simple ordinary differential equation (ODE) called the Gel’fand-Dikii equation, which takes in the function  as input. The ODE is for a special quantity called the diagonal resolvent
as input. The ODE is for a special quantity called the diagonal resolvent  . You integrate that quantity
. You integrate that quantity  with respect to
with respect to  and you’re more or less home. In general, it is a messy quantity that does not integrate to anything nice. But just when the function
and you’re more or less home. In general, it is a messy quantity that does not integrate to anything nice. But just when the function 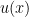 obeys the “string equation” it is supposed to (as dictated by the governing model’s physics), then is a total derivative (a seeming miracle-see later), and the corrections it gives to the density become of just the right form!
obeys the “string equation” it is supposed to (as dictated by the governing model’s physics), then is a total derivative (a seeming miracle-see later), and the corrections it gives to the density become of just the right form!
Those corrections can be called  where the
where the  is the order in perturbation theory.
is the order in perturbation theory. 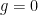 is leading order,
is leading order,  is the torus,
is the torus, 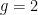 the double torus, etc. Indeed is the number of handles or “genus” of an associated Riemann surface. The one subscript on the other hand, corresponds to the one energy entry available when just discussing the density
the double torus, etc. Indeed is the number of handles or “genus” of an associated Riemann surface. The one subscript on the other hand, corresponds to the one energy entry available when just discussing the density  . All the
. All the  end up being written nicely in terms of a function and its derivatives, evaluated at a special point.
end up being written nicely in terms of a function and its derivatives, evaluated at a special point.
An already nice feature (among many) of the construction was that this one ODE, recursively solved, gave rise to the of many different problems across a range, including certain random matrix models, gravity problems, intersection theory and topology, and so on. All you need to do is change the function . Moreover, for this (wide) class of problems, you can compute the desired results faster and with way less machninery than other methods, such as topological recursion, which was an interesting observation. This includes very famous problems like the Weil-Petersson volumes (of the compactified moduli space  of Riemann surfaces with genus and
of Riemann surfaces with genus and 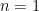 boundaries) and generalisations. Another nice feature is that you also get non-perturbative data beyond the genus expansion, an aspect I explored recently (in this paper) with student Joao Rodrigues, and expert in resurgence techniques.
boundaries) and generalisations. Another nice feature is that you also get non-perturbative data beyond the genus expansion, an aspect I explored recently (in this paper) with student Joao Rodrigues, and expert in resurgence techniques.
 The core breakthrough of the new paper is this: For some time, I’ve wondered how to compute correlators for more energies (amounting to multi-point correlators of
The core breakthrough of the new paper is this: For some time, I’ve wondered how to compute correlators for more energies (amounting to multi-point correlators of  ) in this same way: write them in terms of the same function , and I found a simple way to do it! So now I can write down a formula for any
) in this same way: write them in terms of the same function , and I found a simple way to do it! So now I can write down a formula for any  as a function of and its derivatives, and the method for doing it is very easy because of some features I found for how to organise the computation: A standard picture is that each energy
as a function of and its derivatives, and the method for doing it is very easy because of some features I found for how to organise the computation: A standard picture is that each energy 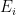 can be thought of as associated with a new “boundary” or “loop” with that label, on a surface with handles, as in the example picture representing
can be thought of as associated with a new “boundary” or “loop” with that label, on a surface with handles, as in the example picture representing  . The main tool in my method is that the appropriate “loop operator” that adds dependence on more energies, normally a fairly complex and formal operation, actually truncates to a very simple operation when things depend only on . Very simple indeed! To add dependence on energy you act with:
. The main tool in my method is that the appropriate “loop operator” that adds dependence on more energies, normally a fairly complex and formal operation, actually truncates to a very simple operation when things depend only on . Very simple indeed! To add dependence on energy you act with:

which can be acted on any function of by just using the usual rules of elementary calculus. It’s bonkers that it is so simple!
So all of a sudden I had a way to swiftly compute all the  , and for a wide variety of problems. This includes (by Laplace transform of the result) having another way of computing the Weil-Petersson volumes
, and for a wide variety of problems. This includes (by Laplace transform of the result) having another way of computing the Weil-Petersson volumes  (of the compactified moduli space
(of the compactified moduli space  of Riemann surfaces with genus and
of Riemann surfaces with genus and  boundaries) and many generalisations of them. (These are mathematical quantities of considerable interest to mathematicians and physicists alike…)
boundaries) and many generalisations of them. (These are mathematical quantities of considerable interest to mathematicians and physicists alike…)
So that was enough for celebration back in late January and early February when I got it all working nicely, but then I began to dig more deeply into why it worked so nicely and got further intrigued. It explained some of the striking earlier things I’d seen in my earlier work (the total derivative result, most notably) and showed what was really going on at a deeper level. I started writing a nice little paper on it, but then realised that one annoying special class of cases where I had to do things a bit differently, using a slightly more general scheme (certain N=1 supersymmetric cases) was actually really really interesting: adding more boundaries/energies turns out to have a really simple pattern, and at a given I could write a closed-form formula for any for the (super) Weil-Petersson volumes! This started because I could see a nice pattern, and then saw in the literature that the mathematician Paul Norbury (U of Melbourne) had used various powerful (and heroic) techniques (from intersection theory and topological recursion) to derive such formulae for  . By time you get to
. By time you get to 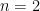 it is already non-trivial, and for
it is already non-trivial, and for 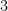 it is a rather intricate formula. I was able to prove them rather swiftly and straightforwardly with my new technique! So of course, I had to accept the challenge: Derive a new formula entirely for
it is a rather intricate formula. I was able to prove them rather swiftly and straightforwardly with my new technique! So of course, I had to accept the challenge: Derive a new formula entirely for 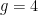 to show that the technique really is predictive. It worked! It’s such a clear method that it is easy to see that this kind of thing works for all , so I am very happy with that result since it also shows how to establish what must be some very powerful mathematics at work.
to show that the technique really is predictive. It worked! It’s such a clear method that it is easy to see that this kind of thing works for all , so I am very happy with that result since it also shows how to establish what must be some very powerful mathematics at work.
(By the way, at high genus the explicit examples I explored in order to check the patterns that I could see appearing become many many pages long, resulting from generating them in Maple. Assembling all the terms of certain types together becomes very unwieldy. I realised that this is a perfect task for AI, and so I used ChatGPT 5.2/5.4 for the first time in a research project, using it to help organise the hundreds (thousands?) of terms to check the patterns I knew were there but needed to verify. I learned a lot about how to make good use of it, and can see it being helpful again in such projects.)
Another nice feature of all this is that it is a very direct recursive method. More direct than topological recursion, another nice (but quite different) framework, developed by Chekhov Eynard and Orantin back in the mid 2000s, and the related recursive frameworks of Mirzakhani for WP volumes, and of Stanford and Witten (for supersymmetric WP volumes). This makes it a vey nice new toolbox for physicists and mathematicians alike. I think of it has having certain special unifying aspects to it since it puts both bosonic and supersymmetric (N=1,2,4) examples under one simple roof, showing that their all have the same structure when written in terms of . This unity is really to do with the fact that underlying all of this stuff (and all of this geometry) is an organisation by a set of PDEs known as the KdV flows, something that goes back to older work from the 1990s kicked off by Edward Witten, but that’s a story for another time.
(You can read the paper here.)
Oh, and I’ve checked my email and there are still no complaints yet, so I’m in decent shape for now…
–cvj
Related

 The core breakthrough of the new paper is this: For some time, I’ve wondered how to compute correlators for more energies (amounting to multi-point correlators of
The core breakthrough of the new paper is this: For some time, I’ve wondered how to compute correlators for more energies (amounting to multi-point correlators of 
It is a great question. I also want to know the answer!
Prof, a naive ask, is there any relationship with paper below for underlying physics other than the KdV flow?
https://arxiv.org/abs/2604.03126
Congrats on getting to this point! I appreciate you’re sharing a glimpse at the mathematical challenges but also the emotional.